Algorithms
-
Computer science is not only about programming, but also about computational thinking. In fact, we can distill computer science and computational thinking into these three ideas:
inputs → algorithms → outputs
As we try to process inputs to produce outputs, we need to come up with algorithms that are not only correct, but also efficient, such that we can get answers quickly to problems with large input sizes.
-
To illustrate how quickly some function might grow, we’ll use an example.
Suppose you could have either
-
A million dollars today, or
-
One penny today, two pennies tomorrow, four cents the next day, …, for a month.
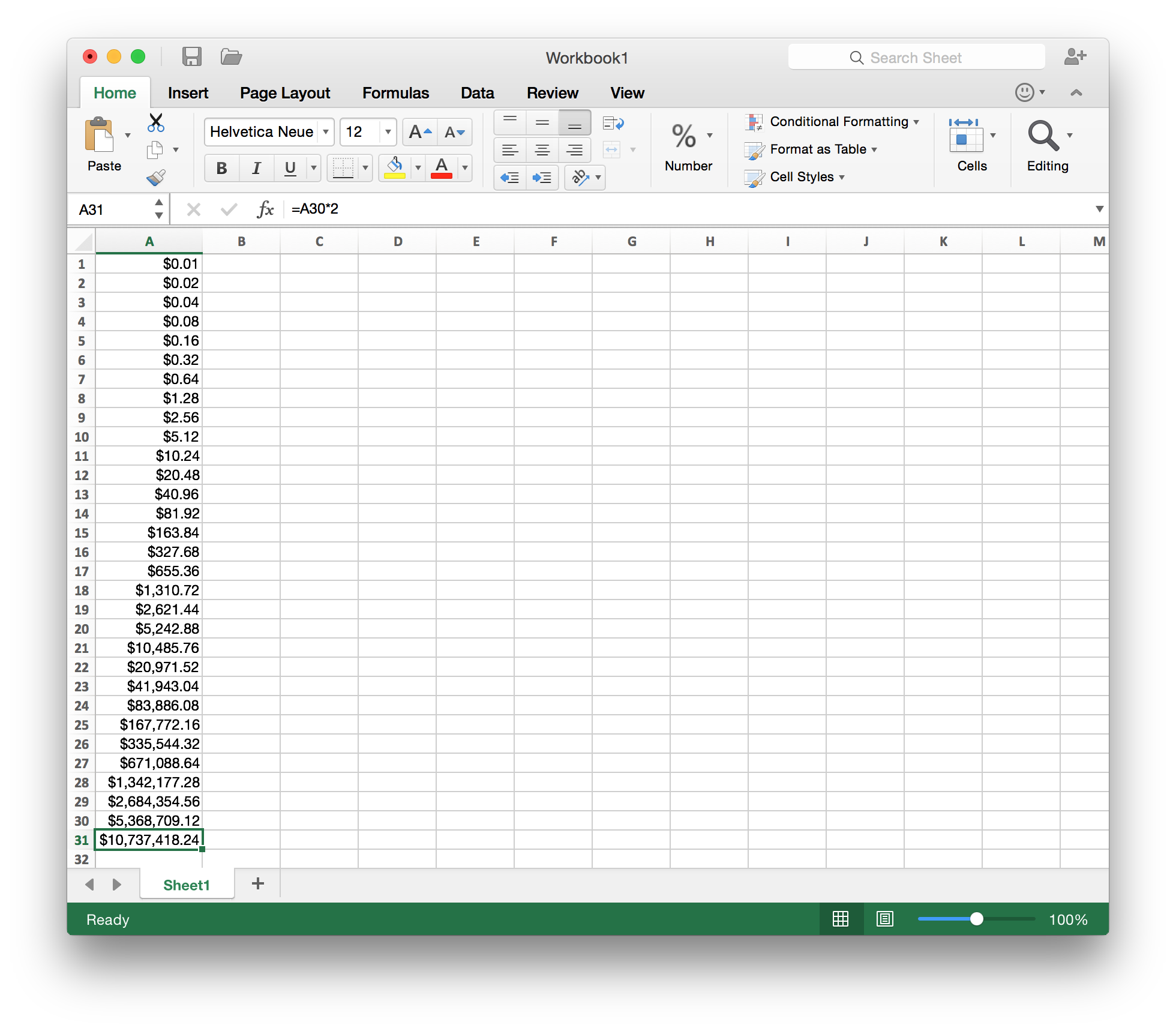
Though a million dollars might sound good, you should pick the latter option whenever asked to make such decision in life. Since the amount of money you get is doubled each day, the total amount of money you get will outgrow one million dollars before the end of the month, as illustrated by this Excel table.
-
-
And so when designing algorithms, we should be careful about how much work the computer will have to do for large inputs. We often worry more when an algorithm executes slowly for large inputs than when it executes quickly for small inputs.
-
But in general, we also should put thought into what the algorithm does and how it does that. If there are any assumptions about the input, we should take advantage of them when we design an algorithm.
Suppose you had to detect if a sorted array
Ahad duplicates. In other words, given a sorted arrayA, find indicesiandjwhereA[i]=A[j]. The array might look something like this:-3
-1
2
4
5
8
10
12
One approach could be to create a list of pairs and iterate through all pairs until you find a pair with the same numbers: (-3, -1), (-3, 2), (-3, 4), …, (10, 12). But your instinct should tell you that this is not the most efficient solution. If is the size of the array, this algorithm would generate pairs. And then you’d have to go through those pairs and look for one with the same numbers. This algorithm would take roughly steps.
A much better algorithm would be to compare each number
A[i]withA[i + 1]. We can do this since the array is sorted! This algorithm would take at most steps. -
Take a look at this table that illustrates the running times (rounded up) of different algorithms on inputs of increasing size, for a processor performing a million high-level instructions per second. In cases where the running time exceeds 1025 years, the algorithm is recorded as taking a very long time.[1]
input size n n log2 n n 2 n 3 1.5n 2n n ! n = 10
< 1 sec
< 1 sec
< 1 sec
< 1 sec
< 1 sec
< 1 sec
4 sec
n = 30
< 1 sec
< 1 sec
< 1 sec
< 1 sec
< 1 sec
18 min
1025 years
n = 50
< 1 sec
< 1 sec
< 1 sec
< 1 sec
11 min
36 years
very long
n = 100
< 1 sec
< 1 sec
< 1 sec
1 sec
12,892 years
1017 years
very long
n = 1,000
< 1 sec
< 1 sec
1 sec
18 min
very long
very long
very long
n = 10,000
< 1 sec
< 1 sec
2 min
12 days
very long
very long
very long
n = 100,000
< 1 sec
2 sec
3 hours
32 years
very long
very long
very long
n = 1,000,000
1 sec
20 sec
12 days
31,710 years
very long
very long
very long
1. Adapted from Table 2.1, p. 34 of Jon Kleinberg and Eva Tardos. 2006. Algorithm Design. Pearson Education, Inc.